April 4, 2013



More photos available in the respective albums - Ajanta caves, Daulatabad fort, and Ellora caves.
More photos available in the respective albums - Ajanta caves, Daulatabad fort, and Ellora caves.
I had organized a Fedora and OpenStack workshop at P.E.S. College of Engineering, Nagsen Vana, Aurangabad, Maharashtra on Saturday, March 2, 2013.

After a formal inauguration at 1000 IST, I introduced the students to communication guidelines, mailing list etiquette, and project guidelines using the “i-want-2-do-project. tell-me-wat-2-do” presentation. The different Fedora sub-projects to which they can contribute to were mentioned. I showed the various free/open source software tools available for them to learn and use. The career options with free/open source software were also discussed. I had asked them to write down any questions they had on the forenoon session, so I could answer them in the afternoon session. Few of their questions:
Post-lunch, I answered their queries in the Q&A session, to the best of my knowledge. I also gave them an introduction on copyright, trademark and patents, and mentioned that IANAL. I then introduced them to the architecture of OpenStack, explaining the individual components, and their functionality. The OpenStack Lab Guide was provided to them to setup their own OpenStack cloud. Some of them had brought their laptops to try it hands-on. I demonstrated the Horizon web interface after starting the required services.

All their computer labs have been migrated to Fedora 17. Thanks to Prof. Nitin Ujgare for working with me in organizing this workshop, and for maintaining the Fedora labs at the Institute. Aurangabad is around 230 km from Pune, and takes around 4 1/2 hours by road. There are frequent bus services between Pune and Aurangabad. You can book bus tickets at Maharashtra State Road Transport Corporation (MSRTC) web site. There are a number of historic places to visit in and around Aurangabad. Few photos taken during the trip are available in my /gallery.
I had presented an introduction to Magit, “Emacs + Magit = Git Magic”, at the Pune Emacs Users’ group meetup on Friday, February 22, 2013. Magit is an Emacs mode that interfaces with Git. Magit doesn’t provide all the interfaces of Git, but the frequently used commands. The user manual was used as a reference. Magit is available in Fedora. You can install it using:
$ sudo yum install emacs-magitThe talk was centered around the notion of writing a poem on Emacs in Emacs, and using magit to revision it. I started an Emacs session, created a directory with Dired mode, and used magit (M-x magit-status) to initialize a git repo. After adding a stanza in the poem, I used the magit commands to stage (s) and commit the same (c, C-c C-c) from the magit-buffer. Another stanza and a README file were then added, and the different untracked, and tracked section visibility options (TAB, S-TAB, {1-4}, M-{1-4}) were illustrated. After adding the third stanza, and committing the same, the short (l l) and long (l L) history formatted outputs were shown. The return (RET) key on a commit in the magit-log history buffer opens a new magit-commit buffer, displaying the changes made in the commit. The sha1 can be copied using the (C-w) shortcut.

The reflogs are visible with the (l h) option from the magit-buffer. The (d) command was used to show the difference between the master and a revision, and (D) for the diff between any two revisions. Annotated tags (t a) and lightweight tags (t t) can be created in magit. Resetting the working tree and discarding the current changes is possible with (X). Stashing (z z) the present changes, applying a stash (a), and killing the stash (k) were demonstrated. An org branch was then created (b n) to write a stanza on org-mode, and then merged (m m) with the master branch. An example of rebasing (R) was also illustrated. The magit-buffer can be refreshed (g) to check the current status of the git repo. Anytime, the magit buffers can be closed with the (q) command. A git command can be invoked directly using (:), and the corresponding output can be viewed with ($), which is shown in a magit-process buffer.
A summary of the various shortcuts are available in the presentation. The poem that I wrote on Emacs, and used in the talk:
Emacs is, an operating system
Which unlike many others, is truly, a gem
Its goodies can be installed, using RPM
Or you can use ELPA, which has already packaged them
You can customize it, to your needs
You can also check EmacsWiki, for more leads
Your changes work, as long as reload succeeds
And helps you with, your daily deeds
People say, it lacks a decent editor
But after using its features, they might want to differ
Using Magit’s shortcuts, you might infer
That it is something, you definitely prefer
Plan your life, with org-mode
You don’t necessarily need, to write code
TODO lists and agenda views, can easily be showed
Reading the documentation, can help you come aboard
Emacs is, a double-edged sword
Its powerful features, can never be ignored
Customization is possible, because of Free Software code
And this is, my simple ode.
GNUnify 2013 was held at Symbiosis Institute of Computer Studies and Research (SICSR), Pune, Maharashtra, India between February 15 to 17, 2013. I attended day one of the unconference.

The first talk that I listened to was by Oyunbileg Baatar on “Screencasting Demos and HowTos”. He mentioned the various free/open source, desktop recording software available. He also gave a demo of recordMyDesktop, and video editing using PiTiVi.
After a short break, and a formal introduction, I began my session for the day - “Introduction to GCC”. Fedora 17 was installed in the labs for the participants to use. I started with a simple hello world example and the use of header files. I also explained the concepts of compilation and linking, and briefed them on the syntax of Makefiles. Examples on creating and using static and shared libraries were illustrated. We also discussed the different warning and error messages emitted by GCC. The platform-specific and optimization options were shown with examples. Students were not familiar with touch typing, and I had to demonstrate the use of Klavaro typing tutor.

The preliminary round for the programming contest was held in the afternoon. Thirty questions on C and systems programming were given to the participants to be answered in thirty minutes. I helped evaluate the answers. The practical test was to be conducted the following day. Thanks to Neependra Khare and Kiran Divarkar for organizing the programming contest.
I also attended the OpenStack mini-conf session in the evening where a demo of OpenStack was given by Kiran Murari. This was followed by a session on “OpenStack High Availability” by Syed Armani. Aditya Godbole’s closing session for the day on an “Introduction to Ruby” was informative. Few photos that were taken are available in my /gallery.
A Fedora workshop was organized at Sandip Institute of Technology and Research Center (SITRC), Nashik, Maharashtra, India from February 2 to 3, 2013.

Day I
I began the day’s proceedings with the “i-want-2-do-project. tell-me-wat-2-do-fedora” presentation in the seminar hall at SITRC. The participants were introduced to mailing list, communication and effective project guidelines when working with free/open source software. This was followed by an introduction on window managers, and demo of the Fedora desktop, GNOME, Fluxbox, and console environments.
After lunch, I gave an introduction on system architecture, and installation concepts. Basics of compilation and cross-compilation topics were discussed. An introduction on git was given using the “di-git-ally managing love letters” presentation. After a short tea break, we moved to the labs for a hands-on session on GCC. This is a presentation based on the book by Brian Gough, “An introduction to GCC”. Practical lab exercises were given to teach students compilation and linking methods using GCC. I also briefed them on the use of Makefiles. C Language standards, platform-specific and optimization options with GCC were illustrated.

Day II
Lab exercises from the GCC presentation were practised on the second day, along with the creation and use of static and shared libraries. The different warning options supported by GCC were elaborated. A common list of error messages that newbies face were also discussed. After the lab session, I introduced them to cloud computing and OpenStack, giving them an overview of the various components, interfaces, and specifications. I also gave them a demo of the OpenStack Essex release running on Fedora 17 (x86_64) with the Horizon web interface.
The college was affiliated to University of Pune, and had deployed GNU/Linux labs for their coursework. Now they are autonomous, and want to explore and expand their activities. They have a local user group called SnashLUG. The college is 15 km away from the city of Nashik, which is around 200 km from Pune. The bus journey from Pune to Nashik takes six hours, and you can book tickets online through Maharashtra State Road Transport Corporation (MSRTC). There is frequent bus service between Pune and Nashik.
Thanks to Rahul Mahale for working with me for the past three months in planning and organizing this workshop. Thanks also to the Management, and Faculty of SITRC for the wonderful hospitality, and their support for the workshop.
Few photos taken during the workshop are available in my /gallery.
“The arrangement (QWERTY) of the letters on a typewriter is an example of the success of the least deserving method.” ~ Nassim Nicholas Taleb
“With early typewriters the mechanical arms would jam if two letters were hit in too rapid a sequence. So the classic QWERTY keyboard was designed to ‘slow down’ typing.” ~ Edward de Bono
The continuous use of the QWERTY keyboard causes pain, and I am forced to rest my fingers. While it is good to take a break, it shouldn’t be done for the wrong reason. I started to look for alternate keyboard layouts to use, and a typing tutor to practise with. Dr. August Dvorak and Dr. William Dealey completed the Dvorak simplified keyboard layout in 1932.

To add the the Dvorak keyboard layout to Gnome, select Applications -> System Tools -> System Settings. Choose “Region and Language”. Under the “Layout” tab, add Dvorak (English). Klavaro is a typing tutor that is available for Fedora. You can install it using:
$ sudo yum install klavaroThere are five levels in Klavaro - introduction, basic course, adaptability, speed, and fluidity. After adding the Dvorak keyboard layout on Fedora, I started the exercises in Klavaro. At home I used Dvorak, while at work I used QWERTY. I was able to quickly reach 30 words per minute (wpm) with Dvorak. When I tried to go beyond 40 wpm, I was unconsciously still thinking, and using the QWERTY keyboard. To break that barrier, I switched full-time to use Dvorak, even at work. Speed was slow, initially, but after a month of practise I passed all the exercises in Klavaro.
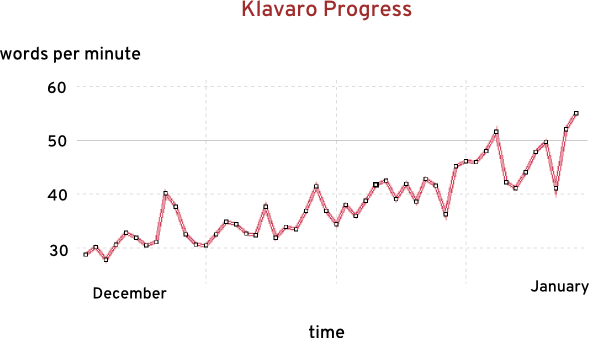
If you are not familiar with touch typing, it is best to start with Dvorak. I can now type continuously for hours, and my fingers don’t hurt. I also do take breaks occasionally.
Give it a try!
The 26th International Conference on VLSI Design 2013 and the 12th International Conference on Embedded Systems was held at the Hyatt Regency, Pune, India between January 5-10, 2013. The first two days were tutorial sessions, while the main conference began on Monday, January 7, 2013.

Day 1: Tutorial
On the first day, I attended the tutorial on “Concept to Product - Design, Verification & Test: A Tutorial” by Prof. Kewal Saluja, and Prof. Virendra Singh. Prof. Saluja started the tutorial with an introduction and history of VLSI. An overview of the VLSI realization process was given with an emphasis on synthesis. The theme of the conference was “green” technology, and hence the concepts of low power design were introduced. The challenges of multi-core and high performance design including cache coherence were elaborated. Prof. Singh explained the verification methodologies with an example of implementing a DVD player. Simulation and formal verification techniques were compared, with an overview on model checking. Prof. Saluja explained the basics of VLSI testing, differences between verification and testing, and the various testing techniques used. The challenges in VLSI testing were also discussed.
Day 2: Tutorial
On the second day, I attended the tutorial on “Formal Techniques for Hardware/Software Co-Verification” by Prof. Daniel Kroening, and Prof. Mandayam Srinivas. Prof. Kroening began the tutorial with the motivation for formal methods. Examples on SAT solvers, boundary model checking for hardware, and bounded program analysis for C programs were explained. Satisfiability modulo theories for bit-vectors, arrays and functions were illustrated with numerous examples. In the afternoon, Prof. Srinivas demoed formal verification for both Verilog and C. He shared the results of verification done for both a DSP and a microprocessor. The CProver tool has been released under a CMBC license. After discussion with Fedora Legal, and Prof. Kroening, it has been updated to a BSD license for inclusion in Fedora. The presentation slides used in the tutorial are available.
Day 3: Main conference
The first day of the main conference began with the keynote by Mr. Abhi Talwalker, CEO of LSI, on “Intelligent Silicon in the Data-centric Era”. He addressed the challenges in bridging the data deluge gap, latency issues in data centers, and energy efficient buildings. The second keynote of the day was given by Dr. Ruchir Puri, IBM Fellow, on “Opportunities and Challenges for High Performance Microprocessor Designs and Design Automation”. Dr. Ruchir spoke about the various IBM multi-core processors, and the challenges facing multi-core designs - software parallelism, socket bandwidth, power, and technology complexity. He also said that more EDA innovation needs to come at the system level.

After the keynote, I attended the “C1. Embedded Architecture” track sessions. Liang Tang presented his paper on “Processor for Reconfigurable Baseband Modulation Mapping”. Dr. Swarnalatha Radhakrishnan then presented her paper on “A Study on Instruction-set Selection Using Multi-application Based Application Specific Instruction-Set Processors”. She explained about ASIPs (Application Specific Instruction Set Processor), and shared test results on choosing specific instruction sets based on the application domain. The final paper for the session was presented by Prof. Niraj K. Jha on “Localized Heating for Building Energy Efficiency”. He and his team at Princeton have used ultrasonic sensors to implement localized heating. A similar approach is planned for lighting as well.
Post-lunch, I attended the sessions for the track “B2. Test Cost Reduction and Safety”. The honourable chief minister of Maharashtra, Shri. Prithviraj Chavan, arrived in the afternoon to formally inaugurate the conference. He is an engineer who graduated from the University of California, Berkeley, and said that he was committed to put Pune on the semiconductor map. The afternoon keynote was given by Mr. Kishore Manghnani from Marvell, on “Semiconductors in Smart Energy Products”. He primarily discussed about LEDs, and their applications. This was followed by a panel discussion on “Low power design”. There was an emphasis to create system level, software architecture techniques to increase leverage in low power design. For the last track of the day, I attended the sessions on “C3. Design and Synthesis of Reversible Logic”. The Keccak sponge function family has been chosen to become the SHA-3 standard.
Day 4: Main conference
The second day of the main conference began with a recorded keynote by Dr. Paramesh Gopi, AppliedMicro, on “Cloud computing needs at less power and low cost” followed by a talk by Mr. Amal Bommireddy, AppliedMicro, on “Challenges of First pass Silicon”. Mr. Bommireddy discussed the factors affecting first pass success - RTL verification, IP verification, physical design, routing strategies, package design, and validation board design. The second keynote of the day was by Dr. Louis Scheffer from the Howard Hughes Medical Institute, on “Deciphering the brain, cousin to the chip”. It was a brilliant talk on applying chip debugging techniques to inspect and analyse how the brain works.
After the keynote, I visited the exhibition hall where companies had their products displayed in their respective stalls. AppliedMicro had a demo of their X-gene ARM64 platform running Ubuntu. They did mention to me that Fedora runs on their platform. Marvell had demonstrated their embedded and control solutions running on Fedora. ARM had their mbed.org and embeddedacademic.com kits on display for students. Post-lunch, was an excellent keynote by Dr. Vivek Singh, Intel Fellow, titled “Duniyaa Maange Moore!”. He started with what people need - access, connectivity, education, and healthcare, and went to discuss the next in line for Intel’s manufacturing process. The 14nm technology is scheduled to be operational by end of 2013, while 10nm is planned for 2015. They have also started work on 7nm manufacturing processes. This was followed by a panel discussion on “Expectations of Manufacturing Sector from Semiconductor and Embedded System Companies” where the need to bridge the knowledge gap between mechanical and VLSI/embedded engineers was emphasized.
Day 5: Main conference
The final day of the main conference began with the keynote by Dr. Vijaykrishnan Narayanan on “Embedded Vision Systems”, where he showed the current research in intelligent cameras, augmented reality, and interactive systems. I attended the sessions for the track “C7. Advances in Functional Verification”, and “C8. Logic Synthesis and Design”. Post-lunch, Dr. Ken Chang gave his keynote on “Advancing High Performance System-on-Package via Heterogeneous 3-D Integration”. He said that Intel’s 22nm Ivy Bridge which uses FinFETs took nearly 15 years to productize, but look promising for the future. Co(CoS) Chip on Chip on Substrate, and (CoW)oS Chip on Wafer on Substrate technologies were illustrated. Many hardware design houses use 15 FPGAs on a board for testing. The Xilinx Virtex-7HT FPGA has analog, memory, and ARM microprocessor integrated on a single chip giving a throughput of 2.8 Terabits/second. He also mentioned that Known Good Die (KGD) methodologies are still emerging in the market. For the last track of the conference, I attended the sessions on “C9. Advances in Circuit Simulation, Analysis and Design”.
Thanks to Red Hat for sponsoring me to attend the conference.
csmith is a tool for testing compilers. It can generate random C programs for the C99 standard. It is now available in Fedora. Install it using:
$ sudo yum install csmithThe following simple bash script, given by the developers, demonstrates its usage:
set -e
while [ true ]
do
csmith > test.c;
gcc-4.0 -I${CSMITH_PATH}/runtime -O -w test.c -o /dev/null;
doneThere are quite a number of options you can use to tell csmith to generate the programs that you want. For example, if you don’t want argc to be passed to the main function, you can use:
$ csmith --no-argcThe main function in the generated C program will resemble:
...
int main (void)
{
...
}The maximum number of fields in a struct that csmith will generate is ten. You can increase it by using the –max-struct-fields option:
$ csmith --max-struct-fields 15A structure that was created with the above option is shown below:
...
struct S1 {
unsigned f0 : 20;
const signed f1 : 2;
volatile signed f2 : 15;
signed f3 : 23;
unsigned f4 : 9;
signed f5 : 1;
volatile uint8_t f6;
const volatile signed f7 : 12;
const volatile signed f8 : 20;
signed f9 : 27;
const unsigned f10 : 11;
uint16_t f11;
};
...csmith also produces a brief summary or statistics on the program it generates. A sample output is shown below:
/************************ statistics *************************
XXX max struct depth: 0
breakdown:
depth: 0, occurrence: 278
XXX total union variables: 13
XXX non-zero bitfields defined in structs: 0
XXX zero bitfields defined in structs: 0
XXX const bitfields defined in structs: 0
XXX volatile bitfields defined in structs: 0
XXX structs with bitfields in the program: 0
breakdown:
XXX full-bitfields structs in the program: 0
breakdown:
XXX times a bitfields struct's address is taken: 0
XXX times a bitfields struct on LHS: 0
XXX times a bitfields struct on RHS: 0
XXX times a single bitfield on LHS: 0
XXX times a single bitfield on RHS: 0
XXX max expression depth: 41
breakdown:
depth: 1, occurrence: 81
depth: 2, occurrence: 19
depth: 3, occurrence: 2
depth: 4, occurrence: 3
depth: 5, occurrence: 1
depth: 10, occurrence: 1
depth: 11, occurrence: 1
depth: 12, occurrence: 1
depth: 13, occurrence: 3
depth: 14, occurrence: 1
depth: 15, occurrence: 1
depth: 16, occurrence: 1
depth: 18, occurrence: 2
depth: 21, occurrence: 2
depth: 28, occurrence: 1
depth: 32, occurrence: 1
depth: 40, occurrence: 1
depth: 41, occurrence: 1
XXX total number of pointers: 191
XXX times a variable address is taken: 88
XXX times a pointer is dereferenced on RHS: 93
breakdown:
depth: 1, occurrence: 85
depth: 2, occurrence: 5
depth: 3, occurrence: 3
XXX times a pointer is dereferenced on LHS: 137
breakdown:
depth: 1, occurrence: 129
depth: 2, occurrence: 5
depth: 3, occurrence: 2
depth: 4, occurrence: 1
XXX times a pointer is compared with null: 16
XXX times a pointer is compared with address of another variable: 2
XXX times a pointer is compared with another pointer: 5
XXX times a pointer is qualified to be dereferenced: 4443
XXX max dereference level: 5
breakdown:
level: 0, occurrence: 0
level: 1, occurrence: 501
level: 2, occurrence: 29
level: 3, occurrence: 13
level: 4, occurrence: 2
level: 5, occurrence: 1
XXX number of pointers point to pointers: 57
XXX number of pointers point to scalars: 132
XXX number of pointers point to structs: 0
XXX percent of pointers has null in alias set: 42.4
XXX average alias set size: 1.73
XXX times a non-volatile is read: 668
XXX times a non-volatile is write: 407
XXX times a volatile is read: 6
XXX times read thru a pointer: 2
XXX times a volatile is write: 1
XXX times written thru a pointer: 0
XXX times a volatile is available for access: 73
XXX percentage of non-volatile access: 99.4
XXX forward jumps: 0
XXX backward jumps: 1
XXX stmts: 81
XXX max block depth: 5
breakdown:
depth: 0, occurrence: 27
depth: 1, occurrence: 18
depth: 2, occurrence: 17
depth: 3, occurrence: 10
depth: 4, occurrence: 5
depth: 5, occurrence: 4
XXX percentage a fresh-made variable is used: 16.2
XXX percentage an existing variable is used: 83.8
********************* end of statistics **********************/If you don’t want the statistics, and would like a brief output, you can use the –concise option with csmith:
$ csmith --conciseYou are encouraged to read the usage guide for more information on using the tool.
The data-memocombinators package provides combinators for creating memo tables. It can build up data similar to a lookup table. It is now available in Fedora. Install it using:
$ sudo yum install ghc-data-memocombinators-develThe time and memory consumption for a command execution can be viewed in ghci by setting the following:
ghci> :set +sSuppose we wish to apply memoization to the Fibonacci function:
import qualified Data.MemoCombinators as Memo
fib = Memo.integral fib'
where
fib' 0 = 0
fib' 1 = 1
fib' x = fib (x-1) + fib (x-2)The 10,000th Fibonacci number using the fib function is returned in a much shorter time in the second attempt:
ghci> fib 10000
...
(0.15 secs, 87703888 bytes)
ghci> fib 10000
...
(0.03 secs, 9652144 bytes)We can also specify a range for which the memoization is to be applied. In the following example, it is applied only for the numbers between 1 and 1000:
import qualified Data.MemoCombinators as Memo
fib2 = Memo.arrayRange (1, 1000) fib'
where
fib' 0 = 0
fib' 1 = 1
fib' x = fib2 (x-1) + fib2 (x-2)Using fib2 to return the 1000th Fibonacci number, we observe the following:
ghci> fib2 1000
...
(0.04 secs, 10804024 bytes)
ghci> fib2 1000
...
(0.02 secs, 7384584 bytes)The mulHundred function takes an integer list as an argument and muliplies each element in the list with 100. We want to tabulate the values for faster lookup using:
import qualified Data.MemoCombinators as Memo
mulHundred = (Memo.list Memo.integral) b
where
b [] = []
b (x:xs) = [100 * x] ++ mulHundred xs Running the mulHundred function in ghci:
ghci> mulHundred [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
[100,200,300,400,500,600,700,800,900,1000]
(0.03 secs, 9592680 bytes)
ghci> mulHundred [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
[100,200,300,400,500,600,700,800,900,1000]
(0.02 secs, 8426040 bytes)We can also apply memoization for quicksort. For example:
import qualified Data.MemoCombinators as Memo
quicksort = (Memo.list Memo.integral) quicksort' where
quicksort' [] = []
quicksort' (p:xs) = (quicksort lesser) ++ [p] ++ (quicksort greater)
where
lesser = filter (< p) xs
greater = filter (>= p) xsSubsequent sorting of the input is faster:
ghci> let input = [x | x <- [100, 99..1]]
(0.02 secs, 7895376 bytes)
ghci> quicksort input
[1,2,..100]
(0.04 secs, 19918312 bytes)
ghci> quicksort input
[1,2,..100]
(0.01 secs, 7925856 bytes)If we would like to create a table of results for the AND operation, we could use Memo.bool:
import qualified Data.MemoCombinators as Memo
andGate = Memo.bool new
where
new x y = x && yFor example:
ghci> False && True
False
(0.02 secs, 8537120 bytes)
ghci> andGate False True
False
(0.02 secs, 8442648 bytes)
ghci> andGate False True
False
(0.01 secs, 7376560 bytes)

